
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- react
- 알고리즘
- 백준 1756
- 백준 2852
- ROWNUM
- 백준 24499 파이썬
- 프로그래머스 조건에 맞는 개발자 찾기
- sql
- 리스트 컴프리헨션
- 백준 11059
- github
- 정규화
- 데이터베이스
- 깃허브
- AWS
- SQLD
- 백준 크리문자열
- 파이썬
- join
- SAA-C02
- Today
- Total
-
[SQLD] #001 데이터 모델링의 이해 - 데이터 모델의 이해 본문
목차
1. 모델링의 이해
2. 데이터 모델의 기본 개념의 이해
3. 데이터 모델링의 중요성 및 유의점
4. 데이터 모델링의 3단계 진행
5. 프로젝트 생명주기(Life Cycle)에서 데이터 모델링
6. 데이터 모델링에서 데이터 독립성의 이해
7. 데이터 모델링의 중요한 세 가지 개념
8. 데이터 모델링의 이해관계자
9. 데이터 모델의 표기법인 ERD의 이해
10. 좋은 데이터 모델의 요소
1. 모델링의 이해
1. 모델링의 정의
Webster 사전
- 가설적 또는 일정 양식에 맞춘 표현
- 어떤 것에 대한 예비 표현으로 그로부터 최종 대상이 구축되도록 하는 계획으로서 기여하는 것
- 복잡한 '현실세계'를 단순화시켜 표현하는 것
- 모델이란 사물 또는 사건에 관한 양상(Aspect)이나 관점(Perspective)을 연관된 사람이나 그룹을 위하여 명확하게 하는 것이다.
- 모델이란 현실 세계의 추상화된 반영이다.
2. 모델링의 특징
추상화, 단순화, 명확화 3대 특징으로 요약할 수 있다.
- 추상화 : 현실세계를 일정한 형식에 맞추어 표현을 한다는 의미
- 단순화 : 복잡한 현실세계를 약속된 규약에 의해 제한된 표기법이나 언어로 표현하여 쉽게 이해할 수 있도록 하는 개념
- 명확화 : 누구나 이해하기 쉽게 하기 위해 대상에 대한 애매모호함을 제거하고 정확하게 현상을 기술하는 것
3. 모델링의 세 가지 관점
모델링은 크게 세 가지 관점인 데이터 관점, 프로세스 관점, 데이터와 프로세스의 상관관점으로 구분하여 설명할 수 있다.

- 데이터 관점 : 업무가 어떤 데이터와 관련이 있는지 또는 데이터간의 관계는 무엇인지에 대해 모델링하는 방법 (What, Data)
- 프로세스 관점 : 업무가 실제하고 있는 일은 무엇인지 또는 무엇을 해야하는지를 모델링하는 방법 (How, Process)
- 데이터와 프로세스의 상관 관점 : 업무가 처리하는 일의 방법에 따라 데이터는 어떻게 영향을 받고 있는지 모델링하는 방법 (Interaction)
2. 데이터 모델의 기본 개념의 이해
1. 모델링의 정의
- 정보시스템을 구축하기 위한 데이터관점의 업무 분석 기법
- 현실세계의 데이터(what)에 대해 약속된 표기법에 의해 표현하는 과정
- 데이터베이스를 구축하기 위한 분석/설계의 과정
2. 데이터 모델이 제공하는 기능
- 시스템을 현재 또는 원하는 모습으로 가시화하도록 도와준다.
- 시스템의 구조와 행동을 명세화 할 수 있게 한다.
- 시스템을 구축하는 구조화된 틀을 제공한다.
- 시스템을 구축하는 과정에서 결정한 것을 문서화한다.
- 다양한 영역에 집중하기 위해 다른 영역의 세부 사항은 숨기는 다양한 관점을 제공한다.
- 특정 목표에 따라 구체화된 상세 수준의 표현방법을 제공한다.
3. 데이터 모델링의 중요성 및 유의점
데이터 모델링이 중요한 이유는 파급효과(Leverage), 복잡한 정보 요구사항의 간결한 표현(Conciseness), 데이터 품질(Data Quality)로 정리할 수 있다.
1. 파급 효과 (Leverage)
데이터 모델 변경 → 표준 영향 분석, 응용 변경 영향 분석 → 해당 분야의 실제적인 변경 작업 → 전체 시스템 구축 프로젝트에서 큰 위험요소
이런 이유로 인해 시스템 구축 작업 중에서 다른 어떤 설계 과정보다 데이터 설계가 더 중요하다.
2. 복잡한 정보 요구사항의 간결한 표현 (Conciseness)
데이터 모델은 구축할 시스템의 정보 요구사항과 한계를 가장 명확하고 간결하게 표현할 수 있는 도구이다.
정보 요구사항을 파악하는 가장 좋은 방법은 수많은 페이지의 기능적인 요구사항을 파악하는 것보다, 간결하게 그려져있는 데이터 모델을 리뷰하면서 파악하는 것이 훨씬 빠르다.
3. 데이터 품질 (Data Quailty)
데이터 품질의 문제가 야기되는 중대한 이유 중 하나가 바로 데이터 구조의 문제이다.
데이터 모델링을 할 때 유의점은 다음과 같다.
1. 중복 (Duplication)
데이터 모델은 같은 데이터를 사용하는 사람, 시간, 그리고 장소를 파악하는데 도움을 준다. 이러한 지식 응용은 데이터베이스가 여러 장소에 같은 정보를 저장하는 잘못을 하지 않도록 한다.
2. 비유연성 (Inflexibility)
데이터의 정의를 데이터의 사용 프로세스와 분리함으로써 데이터 모델링은 데이터 혹은 프로세스의 작은 변화가 애플리케이션과 데이터베이스에 중대한 변화를 일으킬 수 있는 가능성을 줄인다.
3. 비일관성 (Inconsistency)
개발자가 다른 데이터와 모순된다는 고려 없이 데이터를 수정할 수 있기 때문에 데이터 모델링을 할 때 데이터와 데이터간 상호 연관 관계에 대한 명확한 정의를 알아야 한다.
4. 데이터 모델링의 3단계 진행
현실 세계에서 데이터베이스까지 만들어지는 과정
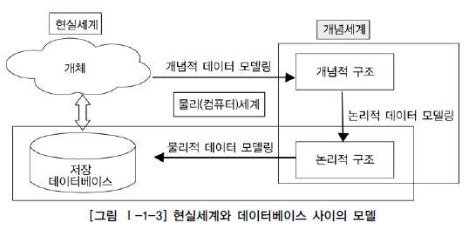
| 개념적 데이터 모델링 | 추상화 수준이 높고 업무중심적이며 포괄적인 수준의 모델링 진행. 전사적 데이터 모델링, EA 수립시 많이 이용 |
| 논리적 데이터 모델링 | 시스템으로 구축하고자 하는 업무에 대해 Key, 속성, 관계 등을 정확하게 표현. 재사용성이 높다. |
| 물리적 데이터 모델링 | 실제로 DB에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계한다. |
1. 개념적 데이터 모델링 (Conceptual Data Modeling)
핵심 엔터티와 그들간의 관계를 발견하고, 그것을 표현하기 위해 엔터티-관계 다이어그램을 생성하는 것이다.
엔터티-관계 다이어그램은 조직과 다양한 데이터베이스 사용자에게 어떤 데이터가 중요한지 나타내기 위해 사용된다.
- 개념 데이터 모델은 사용자와 시스템 개발자가 데이터 요구 사항을 발견하는 것을 지원한다.
- 개념 데이터 모델은 현 시스템이 어떻게 변형되어야 하는가를 이해하는데 유용하다.
2. 논리적 데이터 모델링 (Logical Data Modeling)
논리 데이터 모델링은 데이터베이스 설계 프로세스의 Input으로써 비즈니스 정보의 논리적인 구조와 규칙을 명확하게 표현하는 기법 또는 과정이다. 물리적인 스키마 설계를 하기 전 단계의 '데이터 모델' 상태를 일컫는 말이다.
- 데이터 모델링 과정에서 가장 핵심이 되는 부분이기도 하다.
- 이 단계에서 수행하는 또 한가지 중요한 활동은 정규화이다. 정규화는 논리 데이터 모델 상세화 과정의 대표적인 활동으로, 논리 데이터 모델의 일관성을 확보하고 중복을 제거하여 속성들이 가장 적절한 엔터티에 배치되도록 함으로써 보다 신뢰성 있는 데이터구조를 얻는데 목적이 있다.
3. 물리적 데이터 모델링 (Physical Data Modeling)
물리 데이터 모델링은 논리 데이터 모델이 데이터 저장소로써 어떻게 컴퓨터 하드웨어에 표현될 것인가를 다룬다.
- 이 단계에서 결정되는 것은 테이블, 칼럼 등으로 표현되는 물리적인 저장 구조와 사용될 저장 장치, 자료를 추출하기 위해 사용될 접근 방법 등이 있다.
5. 프로젝트 생명주기 (Life Cycle)에서 데이터 모델링
- Waterfall 기반 : 데이터 모델링의 위치가 분석과 설계 단계로 구분되어 명확하게 정의할 수 있다.
- 정보공학이나 구조적 방법론 : 보통 분석단계에서 업무 중심의 논리적인 데이터 모델링을 수행하고 설계단계에서 하드웨어와 성능을 고려한 물리적인 데이터 모델링을 수행
- 나선형 모델 (RUP, Rational Unified Process 나 마르미) : 업무 크기에 따라 논리적 데이터 모델과 물리적 데이터 모델이 분석, 설계 단계
양쪽에서 수행
6. 데이터 모델링에서 데이터 독립성의 이해
1. 데이터 독립성의 필요성
- 유지보수 비용 증가
- 데이터 복잡도 증가
- 데이터 중복성 증가
- 요구사항 대응 저하
데이터 독립성은 지속적으로 증가하는 유지보수 비용을 절감하고 데이터 복잡도를 낮추며, 중복된 데이터를 줄이기 위한 목적이 있다.
데이터 독립성을 확보하게 되면 다음과 같은 효과를 얻을 수 있다.
- 각 View의 독립성을 유지하고 계층별 View에 영향을 주지 않고 변경이 가능하다.
- 단계별 Schema에 따라 데이터 정의어(DDL)와 데이터 조작어(DML)가 다름을 제공한다.
2. 데이터베이스 3단계 구조
ANSI/SPARC의 3단계 구성이 데이터독립성 모델은 외부 단계와 개념적 단계, 내부적 단계로 구성된 서로 간섭되지 않는 모델을 제시하고있다.

- 외부 단계 : 사용자 개개인이 보는 자료에 대한 관점과 관련이 있는 부분. 즉 사용자가 처리하고자 하는 데이터 유형과 관점, 방법에 따라 다른 스키마 구조를 가지고 있다.
- 개념 단계 : 사용자가 처리하는 데이터 유형의 공통적인 사항을 처리하는 통합된 뷰를 스키마 구조로 디자인한 형태
- 내부적 단계 : 데이터가 물리적으로 저장된 방법에 대한 스키마 구조
3. 데이터 독립성 요소
| 항목 | 내용 |
| 외부 스키마 (External Schema) |
- View 단계 여러개의 사용자 관점으로 구성, 즉 개개 사용자 단계로서 각각의 사용자가 보는 개인적 DB 스키마 - DB의 각각 사용자나 응용프로그래머가 접근하는 DB 정의 |
| 개념 스키마 (Conceptual Schema) |
- 개념 단계 하나의 개념적 스키마로 구성, 모든 사용자 관점을 통합한 조직 전체의 DB를 기술하는 것 - 모든 응용시스템들이나 사용자들이 필요로 하는 데이터를 통합한 조직 전체의 DB를 기술한 것으로, DB에 저장되는 데이터와 그들간의 관계를 표현하는 스키마 |
| 내부 스키마 (Internal Schema) |
- 내부단계, 내부 스키마로 구성, DB가 물리적으로 저장된 형식 - 물리적 장치에서 데이터가 실제적으로 저장되는 방법을 표현하는 스키마 |
4. 두 영역의 데이터 독립성
| 독립성 | 내용 | 특징 |
| 논리적 독립성 | - 개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원하는 것 - 논리적 구조가 변경되어도 응용프로그램에 영향 없음 |
- 사용자 특성에 맞는 변경 가능 - 통합 구조 변경 가능 |
| 물리적 독립성 | - 내부 스키마가 변경되어도 외부/개념 스키마는 영향을 받지 않도록 지원하는 것 - 저장장치의 구조 변경은 응용프로그램과 개념 스키마에 영향 없음 |
- 물리적 구조 영향 없이 개념구조 변경 가능 - 개념구조 영향 없이 물리적인 구조 변경 가능 |
즉, 논리적인 데이터 독립성은 외부의 변경에도 개념스키마가 변하지 않는 특징을 가진다.
5. 사상 (Mapping)
사상은 상호 독립적인 개념을 연결시켜주는 다리를 뜻한다. 데이터 독립성에서는 크게 2가지의 사상이 도출된다.
| 사상 | 내용 | 예 |
| 외부적/개념적 사상 (논리적 사상) |
- 외부적 뷰와 개념적 뷰의 상호 관련성을 정의한다. | - 사용자가 접근하는 형식에 따라 다른 타입의 필드를 가질 수 있다. 개념적 뷰의 필드타입은 변화가 없다. |
| 개념적/내부적 사상 (물리적 사상) |
- 개념적 뷰와 저장된 데이터베이스의 상호 관련성을 정의한다. | - 만약 저장된 데이터베이스 구조가 바뀐다면 개념적/내부적 사상이 바뀌어야한다. 그래야 개념적 스키마가 그대로 남아있게 된다. |
데이터 독립성을 보장하기 위해서는 Mapping을 하는 스크립트(DDL)을 DBA가 필요할 때마다 변경해주어야 한다. 즉, 각 단계(외부, 개념적, 내부적)의 독립성을 보장하기 위해서 변경사항이 발생했을 때 DBA가 적절하게 작업을 해주기 때문에 독립성이 보장된다고도 할 수 있다.
7. 데이터 모델링의 중요한 세 가지 개념
1. 데이터 모델링의 세 가지 요소
- 업무가 관여하는 어떤 것 (Things)
- 어떤 것이 가지는 성격 (Attributes)
- 업무가 관여하는 어떤 것 간의 관계 (Relationships)
데이터 모델링을 완성해가는 핵심 개념 세가지 : 엔터티, 속성, 관계
2. 단수와 집합(복수)의 명명
| 개념 | 복수/집합개념 타입/클래스 |
개별/단수개념 어커런스/인스턴스 |
| 어떤 것 (Thing) |
엔터티 타입 (Entity type) | 엔터티 (Entity) |
| 엔터티 (Entity) | 인스턴스 (Instance) 어커런스 (Occurence) |
|
| 어떤 것 간의 연관 (Associate between Things) |
관계 (Realtionship) | 페어링 (Pairing) |
| 어떤 것의 성격 (Characteristic of a Thing) |
속성 (Attribute) | 속성값 (Attribute Value) |
8. 데이터 모델링의 이해관계자
1. 이해관계자의 데이터 모델링 중요성 인식
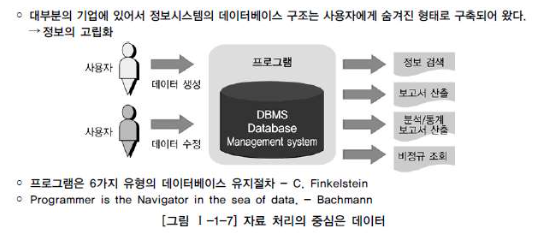
정보 시스템을 개발한다고 할 때 데이터 모델링, 데이터베이스 구축, 구축된 데이터의 적절한 활용은 다른 어떤 일보다 중요하다.
2. 데이터 모델링의 이해관계자
누가 데이터 모델링에 대해 연구하고 학습해야할까?
1. 정보시스템을 구축하는 모든 사람 (전문적으로 코딩하는 사람 포함)
2. IT 기술에 종사하거나 전공하지 않았더라도 해당 업무에서 정보화를 추진하는 위치에 있는 사람
9. 데이터 모델의 표기법인 ERD의 이해
1. 데이터 모델 표기법
1976년 피터첸이 Entity-Relationship Model (E-R Model) 이라는 표기법을 만들었다.
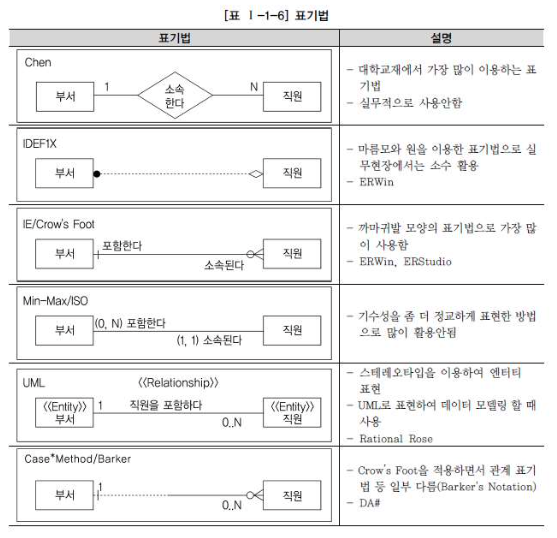
2. ERD(Entity Realtionship Diagram) 표기법을 이용하여 모델링하는 방법
ERD는 각 업무분석에서 도출된 엔터티와 엔터티간의 관계를 이해하기 쉽게 도식화된 다이어그램으로 표시하는 방법으로써 해당 업무에서 데이터의 흐름과 프로세스와의 연관성을 이야기하는 데 가장 중요한 표기법이다.
1. ERD 작업순서는 다음과 같다.
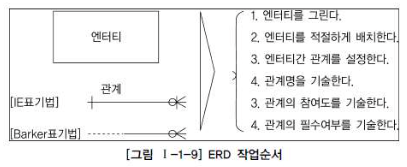
2. 그리고 엔터티를 배치한다. 가장 중요한 엔터티를 왼쪽 상단에 배치하고 이것을 중심으로 다른 엔터티를 나열하면서 전개한다.
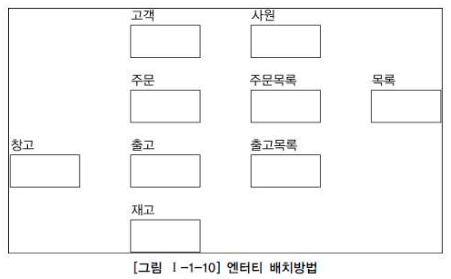
3. ERD 관계석서를 보고 서로 관련 있는 엔터티간에 관계를 설정한다. 초기에는 모두 Primary Key로 속성이 상속되는 식별자 관계를 설정한다. 이때 중복되는 관계나 Circle 관계도 발생하지 않도록 한다.

4. ERD 관계명의 표시 관계 설정이 완료되면, 연결된 관계에 이름을 부여한다.

5. 관계가 참여하는 성격 중 엔터티 내에 인스턴스들이 얼마나 관계에 참여하는지를 나타내는 관계 차수를 표현한다.
10. 좋은 데이터 모델의 요소
1. 완전성 (Completeness)
업무에서 필요로 하는 모든 데이터가 데이터 모델에 정의되어 있어야 한다.
2. 중복 배제 (Non-Redundancy)
하나의 데이터베이스 내에 동일한 사실은 반드시 한번만 기록해야한다.
저장공간의 낭비, 중복 관리되고 있는 데이터의 일관성을 유지하기 위한 추가적인 데이터 조작 등이 대표적으로 낭비되는 비용이다.
3. 업무 규칙 (Business Rules)
데이터 모델에서 매우 중요한 요소 중 하나가 데이터 모델링 과정에서 도출되고 규명되는 수많은 업무 규칙(Business Rules)을 데이터 모델에 표현하고, 이를 해당 데이터 모델을 활용하는 모든 사용자가 공유할 수 있도록 하는 것이다.
이를 통해 해당 데이터 모델을 사용하는 모든 사용자가 해당 규칙에 대해서 동일한 판단을 하고 데이터를 조작 할 수 있게 한다.
4. 데이터 재사용 (Data Reusability)
과거 정보시스템의 데이터 구조의 가장 큰 특징은 데이터 모델이 별도로 존재하지 않고 애플리케이션의 부속품 정도로 인식되어져 온 것이다. 이런 상황에서는 데이터 중복이 많이 발생하고 데이터의 일관성 문제가 심각하게 초래된다. 따라서 데이터가 애플리케이션에 대해 독립적으로 설계되어야만 데이터 재사용성을 향상 시킬 수 있다.
또한 잘 정돈된 방법으로 데이터를 통합하여 데이터의 집합을 정의하고, 이를 데이터 모델로 잘 표현하여 활용한다면 웬만한 업무 변화에도 데이터 모델이 영향을 받지 않고 운용할 수 있게 된다.
5. 의사소통 (Communication)
데이터를 분석하는 과정에서는 자연스럽게 많은 업무 규칙들이 도출된다. 이 과정에서 도출되는 많은 업무 규칙들은 데이터 모델에 엔터티, 서브타입, 속성, 관계 등의 형태로 최대한 자세하게 표현되어야 한다.
이렇게 표현된 많은 업무 규칙들을 해당 정보시스템을 운용/관리하는 많은 관련자들이 설계자가 정의한 업무 규칙들을 동일한 의미로 받아들이고 정보시스템을 활용할 수 있게 하는 역할을 하게 된다. 즉, 데이터 모델이 진정한 의사소통의 도구로써의 역할을 하게 된다.
6. 통합성 (Integration)
가장 바람직한 데이터 구조의 형태는 동일한 데이터는 조직의 전체에서 한번만 정의되고 이를 여러 다른 영역에서 참조, 활용하는 것이다. 물론 이때 성능 등의 부가적인 목적으로 의도적으로 데이터를 중복시키는 경우는 존재할 수 있다. 동일한 성격의 데이터를 한번만 정의하기 위해서는 공유 데이터에 대한 구조를 여러 업무 영역에서 공동으로 사용하기 용이하게 정의할 수 있어야 한다.
출처
이 글의 내용은 모두 한국데이터베이스진흥원이 출판한 SQL 전문가 가이드 2013 Edition을 기본으로 한다.
'SQLD' 카테고리의 다른 글
| [SQLD] #006 데이터 모델과 성능 - 성능 데이터 모델링의 개요 (0) | 2021.04.20 |
|---|---|
| [SQLD] #005 데이터 모델링의 이해 - 식별자 (0) | 2021.04.19 |
| [SQLD] #004 데이터 모델링의 이해 - 관계 (0) | 2021.04.19 |
| [SQLD] #003 데이터 모델링의 이해 - 속성 (0) | 2021.04.16 |
| [SQLD] #002 데이터 모델링의 이해 - 엔터티 (0) | 2021.04.16 |



