
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- github
- 알고리즘
- 데이터베이스
- sql
- ROWNUM
- react
- 백준 24499 파이썬
- 리스트 컴프리헨션
- join
- SQLD
- AWS
- 파이썬
- 백준 11059
- 깃허브
- 프로그래머스 조건에 맞는 개발자 찾기
- 백준 2852
- 정규화
- 백준 1756
- 백준 크리문자열
- SAA-C02
- Today
- Total
-
[파이썬] 중복기사 체크하기 본문
들어가기 전에
내가 랩실에서 했던 프로젝트중 가장 기억에 남는 프로젝트이다. 한줄로 말해보자면 수많은 기사들 중에서 중복되는 기사를 체크하는 프로젝트이다.
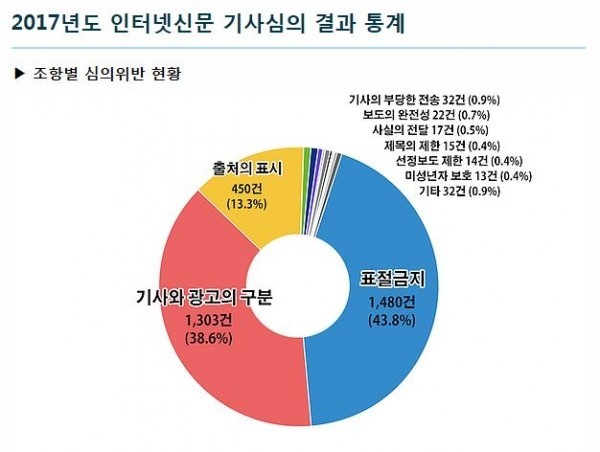
위 통계는 '2017년도 인터넷신문 기사심의 결과 통계' 이다. 가장 많은 부분을 차지하는 것은 표절 기사였다.
심지어는 기자들끼리 사용하는 은어까지 있을 정도였다.
프로젝트에 대하여
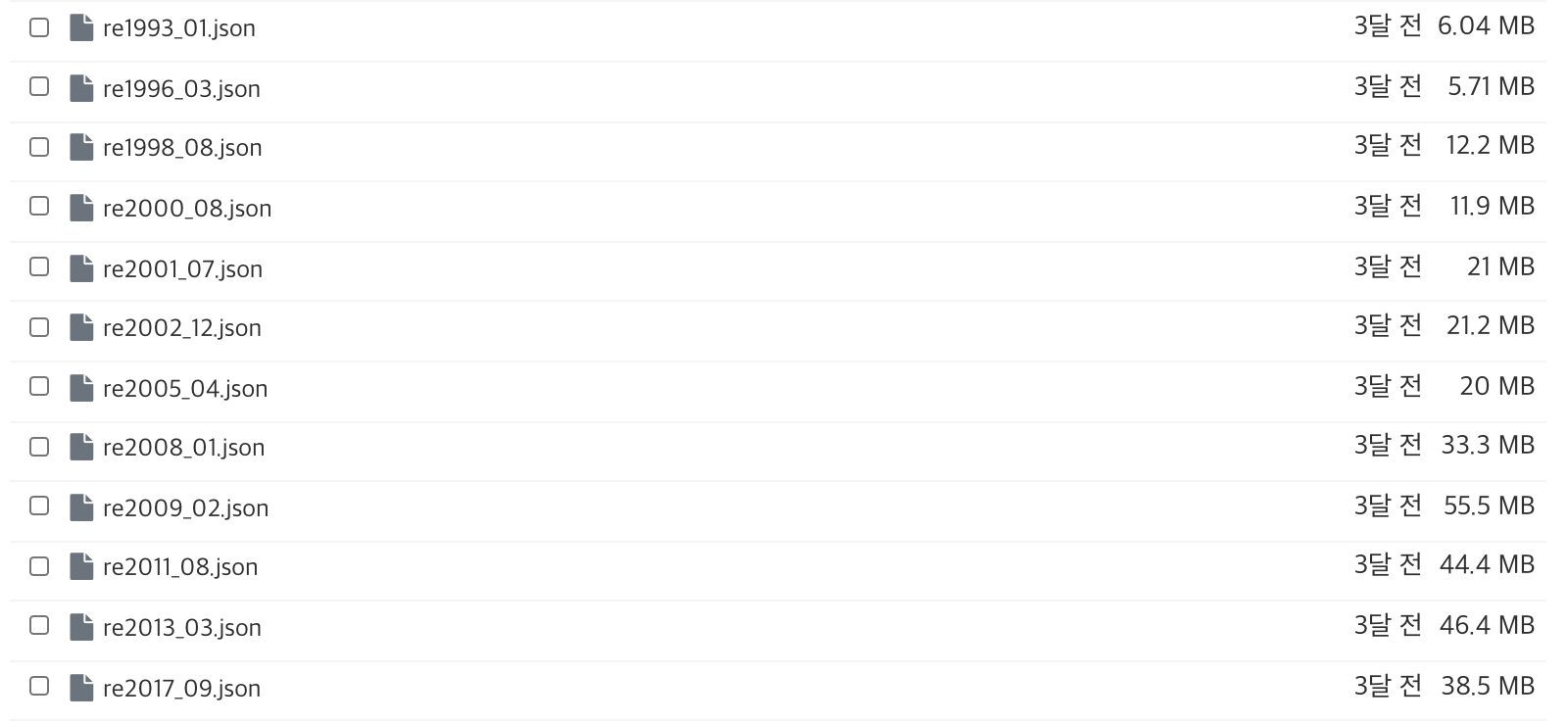
이 프로젝트에서는 공공 뉴스 아카이브인 빅카인즈에서 1993년 ~ 2017년까지의 기사를 약 10만개정도 크롤링 후, 여러 필드를 추가한 json 파일을 사용했다. 파일 이름에 대해 짧게 설명하자면 re1993_01.json 파일은 1993년 01월 01일~31일까지 특정 키워드에 대하여 크롤링한 기사들의 모음이다.
코드의 실행 결과는 아래와 같다.
맨 앞에 있는 숫자(사진에서는 27, 28, 29)는 무작위로 크롤링된 기사들에 순서대로 배정된 index number이다. 중부매일, 경기일보, 충청투데이 등은 기사를 작성한 언론사이고, 그 뒤에 있는 날짜는 기사를 작성한 날짜이다. 기사 제목과 본문을 같이 출력한다.

알고리즘
중복기사를 검출하는 알고리즘은 총 여섯 단계로 이루어져있다.
1. 파일 읽어오기
json 파일을 읽어와서 data frame 으로 만든다. 이때 json 파일에 있는 여러 필드들도 각각의 data frame 으로 만들어준다.
2. 기사 전처리
KoNLPy 패키지의 Okt 형태소 분석기를 사용하여 기사 본문의 전처리를 한다.
3. tf-idf 값 계산
scikit learn 내의 라이브러리인 tf-idf를 사용하여 기사 각각의 tf-idf 값을 계산한다.
4. K-Means 군집화
scikit learn 내의 라이브러리인 KMEANS를 사용하여 비슷한 주제를 가진 기사들을 그룹화한다. 여기서 k 값은 √( 로 정했다.
5. countVectorizer
scikit learn 내의 라이브러리인 countVectorizer를 사용하여 기사 본문에 나오는 단어 빈도를 계산하여 2차원 행렬로 만든다.
6. 코사인 유사도 검사
앞 단계에서 생성된 행렬을 가지고 기사간의 코사인 유사도를 계산한다. 코사인 유사도 결과가 0.9 이상이면 중복기사라고 판단한다.
아래에서 단계별로 자세히 설명하겠다.
1. json 파일을 Data frame 으로 만들기

위의 사진은 크롤링한 기사들에 여러 필드를 추가하는 전처리가 완료된 json 파일의 내부이다.
- searchkey : 어떤 키워드로 기사를 검색했는지
- url : 기사를 크롤링한 url
- period : 기사가 작성된 기간 (한달 단위)
- company : 기사를 작성한 언론사
- title : 기사의 제목
- genre,date, name : 기사의 카테고리와 기사가 작성된 날짜
- doc : 기사 본문
나는 테스트 파일로 1993년 1월에 작성된 기사들을 사용했다. 아래의 식을 통해 json 파일을 data frame 으로 만든다.
df = pd.read_json('./re1993_01.json')
2. 기사 전처리
정확한 tf-idf 값의 계산을 위해 기사를 전처리하는 과정이다. 전처리 후에는 명사, 알파벳, 숫자만 남게 했다. 아래는 전처리 함수이다.
def tokenizer(raw, pos=["Noun","Alpha","Number"], stopword=[]): #현재는 "Verb" 제외
return [
word for word, tag in okt.pos(
raw,
norm=True,
stem=True
)
if len(word) > 1 and tag in pos and word not in stopword
]
3. tf-idf 값 계산
scikit learn 내의 라이브러리인 tf-idf를 사용하여 기사 각각의 tf-idf 값을 계산한다. 실행 후 결과는 이렇게 이차원배열이 만들어진다.

tf-idf 에 대한 설명은 여기를 통해 확인할 수 있다.
4. K-Means 군집화
scikit learn 내의 라이브러리인 KMEANS를 사용하여 비슷한 주제를 가진 기사들을 그룹화한다. 여기서 k 값은 √( 로 정했다. 아래 논문을 참고했다.
차수진, 이주영, 김재성, 서영균. (2019). FLASH: 많은 수의 뉴스 기사를 중복 제거할 수 있는 메모리-효율적이고 확장성 있는 방법. 한국정보과학회 학술발표논문집, (), 97-99.
내가 사용한 json 파일 내의 기사는 1787 개이므로, 위의 수식을 적용하면 총 14개의 그룹이 만들어진다.
실행 후 결과는 다음과 같다.

사진에 있는 리스트는 각각의 기사가 몇번째 그룹인지를 표시한다.
즉, [3, 7, 10, ...] 에서 첫번째 기사는 3번 그룹이고, 두번째 기사는 7번 그룹, 세번째 기사는 10번 그룹이다.
5. countVectorizer
기사 본문에 나오는 단어의 빈도를 계산하여 이차원배열로 만드는 함수이다. 아래는 함수 코드이다.
vectorize = CountVectorizer(
tokenizer=tokenizer,
min_df=2 # min_df = 0.01 : 문서의 1% 미만으로 나타나는 단어 무시
# min_df = 10 : 문서에 10개 미만으로 나타나는 단어 무시
# max_df = 0.80 : 문서의 80% 이상에 나타나는 단어 무시
# max_df = 10 : 10개 이상의 문서에 나타나는 단어 무시
)실행했을때의 결과는 다음과 같다.

6. 코사인 유사도 검사
앞 단계에서 생성된 행렬을 가지고 같은 그룹 내 기사간의 코사인 유사도를 계산한다. 코사인 유사도 결과가 0.9 이상이면 중복기사라고 판단한다. 코사인 유사도를 검사한 결과가 이렇게 삼차원리스트이기 때문에 코사인 유사도가 0.9 이상인 기사를 찾아서 출력하려면 삼중 for문을 사용해야했다.

for h in range(len(similarity_simple_pair)):
for i in range(len(similarity_simple_pair[h])):
for j in range(len(similarity_simple_pair[h][i])):
if(0.9 < similarity_simple_pair[h][i][j] <= 0.99999):
if(i not in checked[h]):
checked[h].append(i)
if(j not in checked[h]):
checked[h].append(j)
중복기사라고 판단된 기사들의 인덱스는 checked 라는 리스트에 추가한다. 마지막 단계에서 기사를 출력할 때 기사가 들어있는 리스트에서 checked 에 저장되어있는 인덱스만으로 기사를 가져오기 위함이다.
7. 결과 출력하기
기사가 들어있는 리스트(dflist 로 정의해놓았다.)에서 저장된 인덱스만으로 기사를 가져오니, 실제 기사 본문과 기사의 인덱스가 일치하지 않는 문제가 발생했다. 나중에 코드를 처음부터 꼼꼼히 살펴보니 dflist 는 처음에 기사 모두를 불러온 리스트였고, 중복기사를 가져올 때는 Kmeans 단계에서 분류한 그룹에서 가져와야 했다. 그 결과 성공적으로 중복기사를 검출한 모습을 볼 수 있다.

또한 전체 기사 1787개 중, 중복이라고 체크된 기사의 개수는 142개였다.

보완해야할 점
자연어처리 부분과 scikit-learn 에서는 완전 노베이스 상태로 진행했기 때문에 코드가 깔끔하지도 않고 아쉬운 부분도 많았다. 그래서 프로젝트를 마치고 몇가지 보완하고싶은 부분이 있어 짧게 정리하고자 한다.
1. 중복되는 기사중 어느것을 메인으로 할것인가?
첫번째는 중복되는 기사중 어느것을 메인으로 할지에 대해 고민하지 않았다. 아래 사진으로 예를 들어보자면, 두개의 기사가 서로 중복기사로 검출되었다. 하지만 이 결과는 유저에게 단지 두개가 중복된다는 사실만을 제공할 뿐이다. 만약 중복기사중 한개의 기사만 남기고 삭제한다고 했을 때 어떤 기사를 남겨야할까?

2. 코드의 시간복잡도 향상
위에서도 말했듯이 for 문이 상당히 많이 쓰였다. 교수님께서 속도는 신경쓰지 말고 정확도에 초점을 맞추라고 하신 말씀을 너무 새겨들은 것 같다. 또한 마지막에 중복기사들을 쉽게 출력하기 위해 기사 본문이나 제목, 날짜, 언론사 등을 모두 각각의 list 에 넣어놨는데 이 과정에서도 코드가 복잡해졌다.
3. 최근 기사로 다시 해보기
크롤링된 데이터중 가장 최근 기사는 2017년이었다. 하루만 지나도 새로운 주제들이 쏟아져 나오는 상황에서 3년, 길게는 25년까지 지난 기사를 사용한다는게 아쉬웠다. 시간이 된다면 최근에 핫한 키워드로 다시 한번 크롤링을 진행해보고 싶다.
4. 한 그룹 내에서도 주제가 다른 중복기사가 생긴다는 것
내가 짠 프로그램은 K-means Clustering 을 한 후에 같은 그룹 내에서 중복기사를 찾아내는 방식이다. 그렇기 때문에 아래 사진처럼 같은 그룹 내에서 중복기사가 여러쌍 나온다. (49번-51번이 서로 중복기사 , 67번-69번이 서로 중복기사)
아직 이 문제를 해결할 방법을 찾지 못했다.

5. 객관적인 척도가 없어 프로그램의 정확도 판단이 힘들다는 것
난 이게 가장 큰 문제점이라고 생각한다. 내가 만든 프로그램이 얼마나 정확한지를 수치로 판단할 수 없다는 것이다. 정확도 판단을 계산하기 위해서는 다음과 같은 계산이 필요하다.
(내 프로그램이 검출한 중복기사의 수 / 실제 중복기사의 수) * 100
내 프로그램이 출력한 중복기사들 중에서는 육안으로 확인했을 때 오류가 없었다. 하지만 실제 중복기사의 수를 알지 못하기 때문에 정확도를 계산할 수 없었고, 그렇다고 1800개 가량의 기사를 일일이 눈으로 읽고 매칭시킬수도 없는 노릇이었다. 이 문제가 해결된다면 훨씬 값진 프로젝트가 될 것이라고 생각한다.
'Project' 카테고리의 다른 글
| 구글 form의 응답값을 구글 spreadsheet에 자동으로 저장하기 (0) | 2021.04.15 |
|---|---|
| [AWS] AWS Compute Optimizer를 사용한 딥러닝용 인스턴스 분석 (0) | 2021.01.26 |

