
Notice
Recent Posts
Recent Comments
01-26 08:15
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 깃허브
- github
- 백준 2852
- join
- 알고리즘
- 백준 1756
- SQLD
- AWS
- 백준 11059
- react
- 백준 24499 파이썬
- 파이썬
- 백준 크리문자열
- 데이터베이스
- sql
- 정규화
- 프로그래머스 조건에 맞는 개발자 찾기
- 리스트 컴프리헨션
- SAA-C02
- ROWNUM
Archives
- Today
- Total
-
[AWS] AWS Compute Optimizer를 사용한 딥러닝용 인스턴스 분석 본문
반응형
이 프로젝트는 몇가지 종류의 인스턴스에서 딥러닝 코드를 반복적으로 실행하고, Compute Optimizer에서 그 결과를 체크해보는 간단한 프로젝트이다.
1. 실행 환경
MacBook Pro (13-inch, 2016, Four Thunderbolt 3 Ports)에서 ssh를 통한 EC2 Instance 접속
2. 실험 조건
총 두개의 실험을 진행했다.
1번 실험은 한번만 돌려서 측정했다. 2번 실험은 인스턴스 생성 후 계속 진행하였고, 2-3일정도 멈추지 않고 진행하였다.
실험 #1
두개의 인스턴스에서 같은 네트워크 환경으로 동시에 돌렸을 때, 각각의 시간 측정
- batch size = 128, epoch = 277로 고정
- 인스턴스는 c5.2xlarge 와 c5.4xlarge
# Based on AWS DeepLearning AMI with Ubuntu 18.04
sudo bash
# Set the CUDA Version as 10.1
# TensorFlow Profiler and CUPTI Doesn't Work on CUDA 10.2
# At 2020. 05. 03
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-10.1 /usr/local/cuda
# Upgrade pip3 and install tensorflow, tensorboard, dataset packages
pip3 install --upgrade pip
pip3 install tf-nightly
pip3 install tb-nightly
pip3 install tensorboard_plugin_profile
pip3 install tensorflow_datasets
vi mnist_lenet5.py
실험 #2
세개의 인스턴스에서 같은 네트워크 환경으로 동시에 돌렸을 때, Compute Optimizer로 결과 분석
- batch size = 최소 16 ~ 최대 256까지 순차적으로 변경, epoch = 100으로 고정
- 인스턴스는 r5.2xlarge 와 c5.2xlarge 와 c5.4xlarge
3. 실험 코드
Setting
# Based on AWS DeepLearning AMI with Ubuntu 18.04
sudo bash
# Set the CUDA Version as 10.1
# TensorFlow Profiler and CUPTI Doesn't Work on CUDA 10.2
# At 2020. 05. 03
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-10.1 /usr/local/cuda
# Upgrade pip3 and install tensorflow, tensorboard, dataset packages
pip3 install --upgrade pip
pip3 install tf-nightly
pip3 install tb-nightly
pip3 install tensorboard_plugin_profile
pip3 install tensorflow_datasets
vi mnist_lenet5.py
MNIST Code + Time
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
from packaging import version
import time
import pickle
import os
import tensorflow as tf
import argparse
time_start = time.perf_counter()
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=128, type=int)
parser.add_argument('--epoch',default=277,type=int)
args = parser.parse_args()
batch_size = args.batch_size
num_classes = 10
epochs = args.epoch
# input image dimensions
img_rows, img_cols = 32, 32
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
if tf.keras.backend.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 3, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 3, img_rows, img_cols)
input_shape = (3, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 3)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 3)
input_shape = (img_rows, img_cols, 3)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(5, 5), activation='relu', input_shape=input_shape))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(64, (5, 5), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
time_end = time.perf_counter()
time_taken = time_end-time_start
print("runtime: %.4f sec" % (time_taken))
Run Shell Script
# batch size를 변경하며 코드를 실행함
# Batch 16
echo '@@@@@@@ Batch 16 -1 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 16 --epoch 100
sleep 5
echo '@@@@@@@ Batch 16 -2 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 16 --epoch 100
sleep 5
echo '@@@@@@@ Batch 16 -3 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 16 --epoch 100
sleep 5
# Batch 32
echo '@@@@@@@ Batch 32 -1 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 32 --epoch 100
sleep 5
echo '@@@@@@@ Batch 32 -2 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 32 --epoch 100
sleep 5
echo '@@@@@@@ Batch 32 -3 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 32 --epoch 100
sleep 5
# Batch 64
echo '@@@@@@@ Batch 64 -1 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 64 --epoch 100
sleep 5
echo '@@@@@@@ Batch 64 -2 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 64 --epoch 100
sleep 5
echo '@@@@@@@ Batch 64 -3 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 64 --epoch 100
sleep 5
# Batch 128
echo '@@@@@@@ Batch 128 -1 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 128 --epoch 100
sleep 5
echo '@@@@@@@ Batch 128 -2 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 128 --epoch 100
sleep 5
echo '@@@@@@@ Batch 128 -3 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 128 --epoch 100
sleep 5
# Batch 256
echo '@@@@@@@ Batch 256 -1 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 256 --epoch 100
sleep 5
echo '@@@@@@@ Batch 256 -2 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 256 --epoch 100
sleep 5
echo '@@@@@@@ Batch 256 -3 @@@@@@@'
python3.6 mnist_lenet5.py --batch_size 256 --epoch 100
sleep 5
AWS Compute Optimizer에서 Memory Utilization이 안뜨는 경우
아래 코드를 사용하여 AWS CloudWatch Agent를 설치해야한다.
#ubuntu의 경우 사용할 수 있는 코드
> wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
> sudo dpkg -i -E ./amazon-cloudwatch-agent.deb
#root directory로 간 상황에서
> cd opt/aws/amazon-cloudwatch-agent/bin
> ./amazon-cloudwatch-agent-ctl -a start -m ec2 -c ssm:AmazonCloudWatch-linux -s
> service amazon-cloudwatch-agent status
4. 실험 결과
1번 실험 결과
모델의 학습 시간
c5.2xlarge 의 경우 277 epoch를 돌리는데 걸리는 시간 : 4634.7134 sec
c5.4xlarge 의 경우 277 epoch를 돌리는데 걸리는 시간 : 2740.6848 sec
2번 실험 결과 (Compute Optimizer 결과)
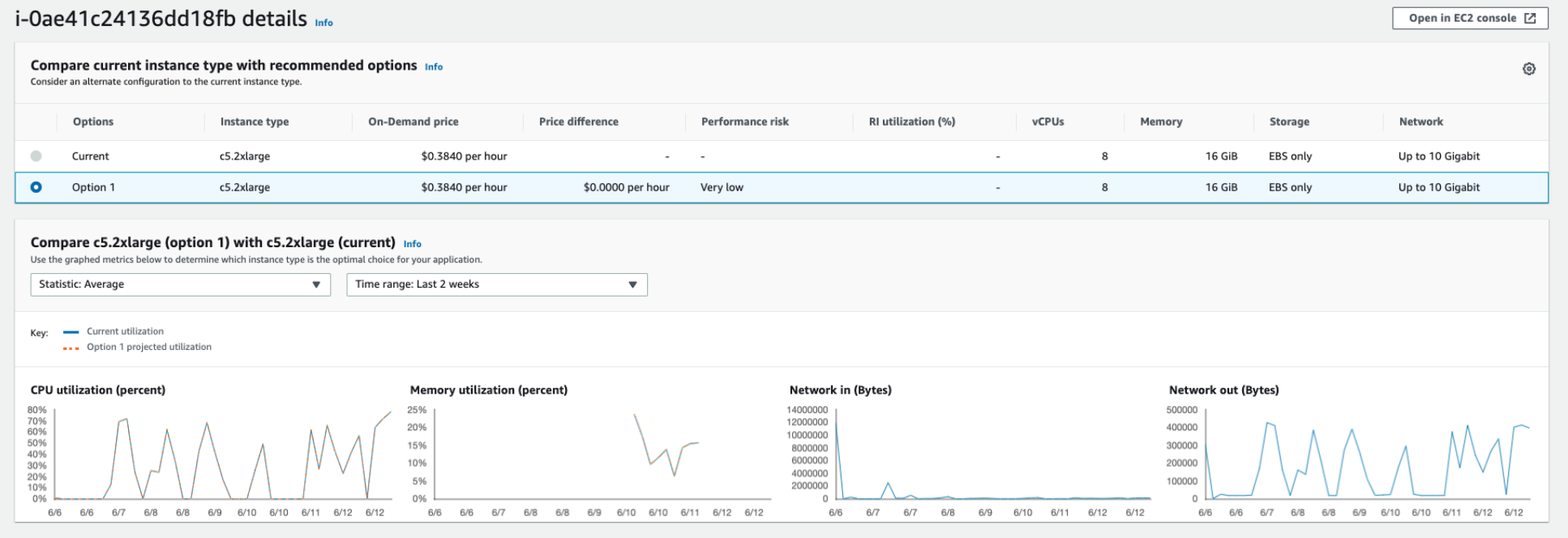
c5.2xlarge (Optimized)
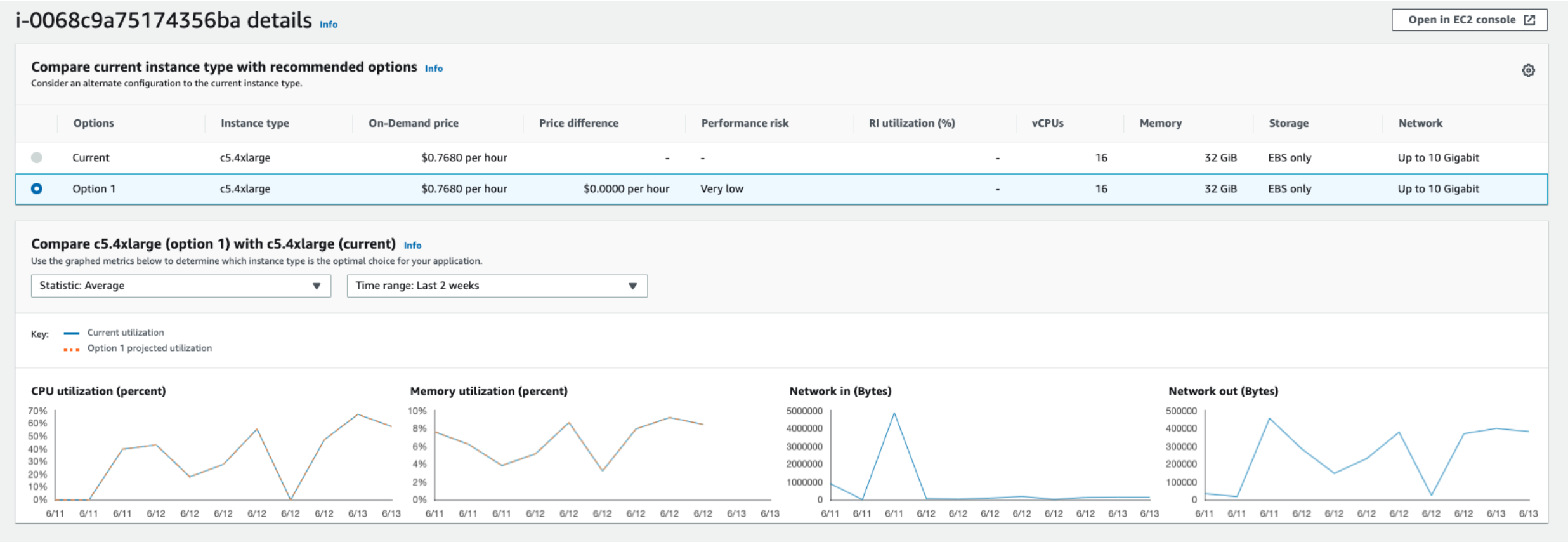
c5.4xlarge (Optimized)
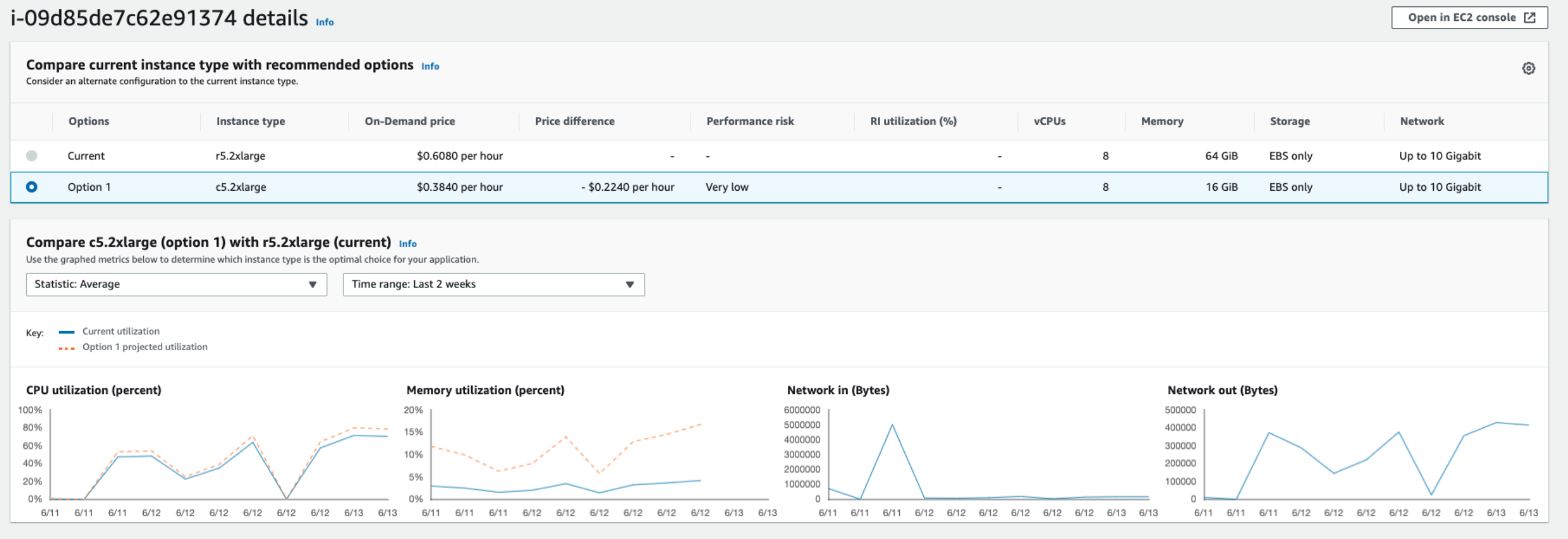
r5.2xlarge (Over provisioned)
이 인스턴스는 현재 Over provisioned 된 상태로, Compute Optimizer는 인스턴스를 c5.2xlarge로 변경할 것을 권장했다.
반응형
'Project' 카테고리의 다른 글
| 구글 form의 응답값을 구글 spreadsheet에 자동으로 저장하기 (0) | 2021.04.15 |
|---|---|
| [파이썬] 중복기사 체크하기 (0) | 2021.01.14 |
'Project' Related Articles
more


Comments